Seule, une "checklist" ne vaut rien.
Joshua Copeland et Jean-Paul Lizotte

Image générée par l'IA.
Tout le monde aime une liste de contrôle (checklist). Microsoft les publie. Les consultants facturent par eux. Les RSSI s'accrochent à eux. Mais voici ce qu'on pense discrètement, mais dit à haute voix: les meilleures pratiques Azure consistent davantage à réussir les audits qu'à arrêter les attaquants.
Ils ont fière allure dans un rapport du conseil. Ils cochent la case de conformité. Mais ils ne reflètent pas la façon dont les adversaires se œuvrent, exploitent et pivotent réellement dans les environnements infonuagiques. Ce qui nous reste, c'est le théâtre de la sécurité; l'illusion de la sécurité sans la substance de la résilience.
Le problème des "meilleures pratiques"
Il s'agit de marketing, pas de sécurité.
La plupart des "meilleures pratiques" d'Azure sont écrites pour montrer à quel point la plateforme est soignée, et non comment elle résiste réellement aux attaques. Il s'agit de configurations généralisées et conviviales destinées à avoir fière allure dans une présentation PowerPoint ou à satisfaire à un audit de conformité. Le problème? Les vrais adversaires ne se soucient pas des tableaux de bord propres ou des politiques bien alignées. Ils recherchent les exceptions, les anciens comptes que personne n'a touchés, le directeur de service mal configuré qui tient tranquillement l'administration globale. Les meilleures pratiques créent l'illusion d'une forteresse, mais trop souvent c'est une découpe en carton... parfaite pour une démonstration de vente, inutile en cas de brèche.
Un jeu de chat et souris.
Au moment de la publication des directives, les attaquants ont déjà changé de tactique. Les kits de contournement de l'authentification multifacteur, le vol de jetons et les fédérations d'identités mal configurées ne sont pas abordés dans les PDF sur papier glacé. Lorsque les menaces changent quotidiennement, elles ne seront jamais exactes au paysage actuel des menaces.
Ils mesurent la conformité, pas la résilience.
Réussir un benchmark de sécurité Azure, c'est comme réussir un examen à livre ouvert. Cela ne prouve pas que vous pouvez performer sous pression; Cela prouve que vous pouvez lire et trouver les réponses. Ce n'est pas mal, mais n'importe qui peut cliquer sur une liste de contrôle, activer quelques bascules et générer un rapport indiquant "sécurisé". Mais cela ne signifie pas que votre environnement peut résister au vol de jetons, à l'élévation de privilèges ou à un déplacement latéral à travers une identité mal configurée. La conformité montre que vous avez suivi la recette. La résilience prouve que vous pouvez improviser lorsque l'alarme incendie se déclenche et que la recette ne s'applique plus. Les attaquants ne se soucient pas de savoir si vous avez obtenu un score de 100% sur un point de référence, ils se soucient des espaces que vous avez laissés entre les lignes.
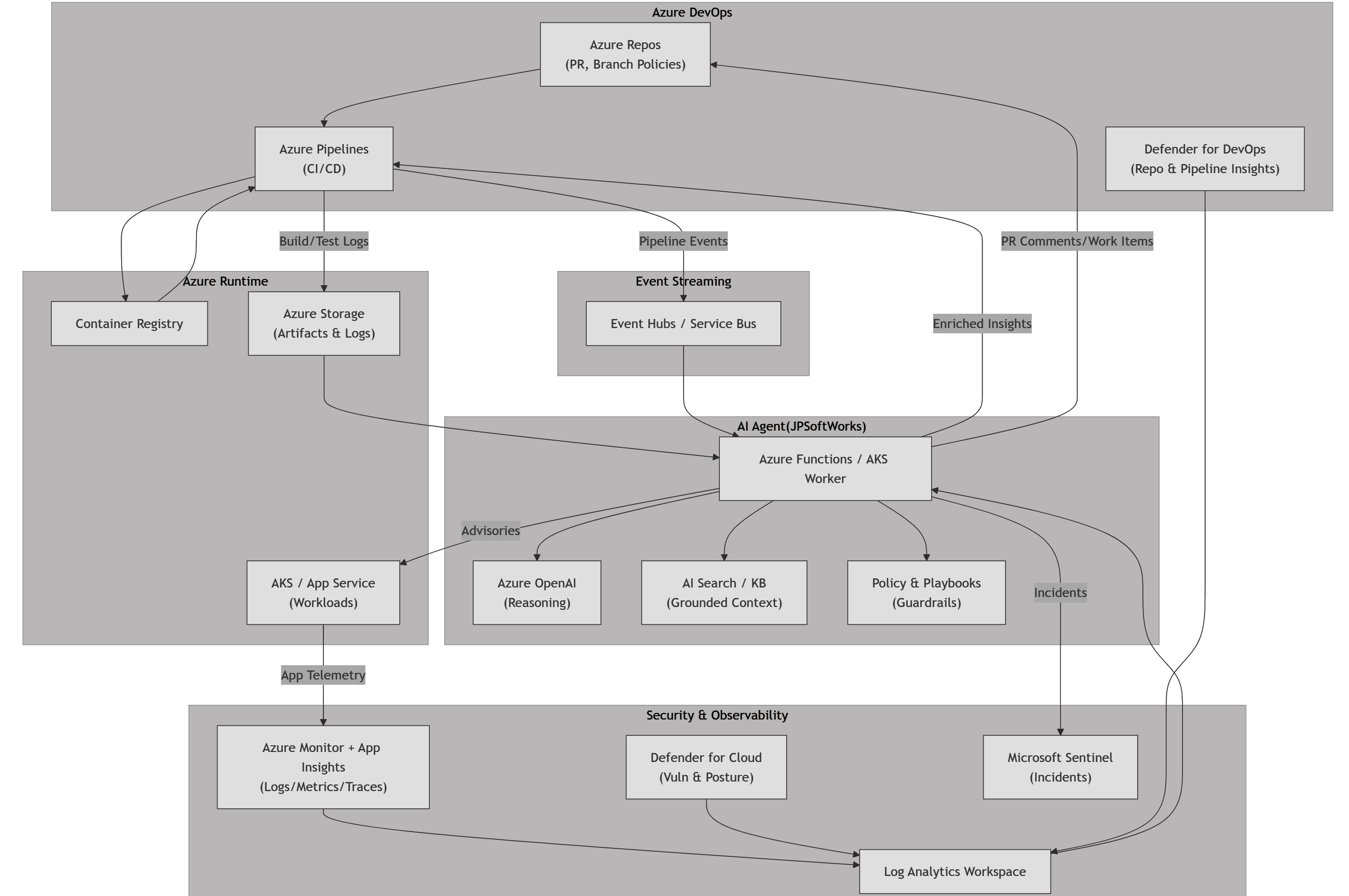
Le point de vue de JP: Bâtir une résilience réelle
- L'automatisation dans un souci de résilience. Ne vous contentez pas d'automatiser les bascules; Automatisez la récupération et l'auto-réparation. Les pipelines d'infrastructure qui détectent la dérive et corrigent automatiquement réduisent votre surface d'attaque plus rapidement que les correctifs manuels.
- L'examen par les pairs comme contrôle de sécurité de première classe. Les déploiements automatisés nécessitent des frictions humaines aux bons endroits. L'examen par les pairs des changements d'architecture et des demandes de tirage IaC détecte les types d'erreurs qui mènent à l'élévation des privilèges. C'est moins tape-à-l'œil qu'un tableau de bord, mais beaucoup plus efficace.
- Protection des données sur le terrain. Le chiffrement des disques et des objets blob est évident. Le chiffrement des champs sensibles dans les bases de données et les flux de messages est ce qui frustre les attaquants. Même s'ils pivotent, ce qu'ils tirent est inutile sans clés.
- Exploitation forestière résiliente. Si vos journaux ne vivent que dans le même locataire que vous défendez, ils sont à un rm -rf de disparaître. L'expédition des journaux dans un environnement isolé garantit que vos services judiciaires survivent à l'atteinte.
C'est ainsi que vous passez du théâtre à l'ingénierie de la résilience.
Au-delà de la liste de contrôle: ce qui fonctionne réellement
Bases de référence axées sur les menaces
- Analyse des journaux.
- Enregistrez tout et ayez des outils qui analysent ces journaux pour détecter des modèles "inhabituels" répétés, y compris le volume d'accès.
- Examinez fréquemment les registres.
- Utilisez des pots de miel (honeypots) ou des ressources de tromperie pour détecter rapidement les sondages d'identité et les attaques brutes d'identifiants.
- Alternez régulièrement les secrets et les clés des principaux de service, l'automatisation appliquant les horaires de rotation.
- Créez des tableaux de bord de comportement "normaux" de base et alertez sur les tendances des écarts plutôt que sur des seuils bruts.
- Tirez parti de l'IA pour signaler les tendances ou les indices cachés. Mais ne vous y fiez pas!
Contrôles du périmètre de l'abus d'identité
-
Prenez le temps d'y accéder. -
L'accès anonyme devrait être refusé à la frontière. -
Appliquez des politiques d'accès conditionnel qui évaluent la posture des appareils, l'emplacement du réseau et l'analyse comportementale. -
Limitez l'accès "juste-à-temps" avec une expiration automatisée pour les rôles élevés (Privileged Identity Management dans Azure AD). -
Cartographiez et élaguez les "identités fantômes" (comptes de service, utilisateurs invités obsolètes) à une cadence mensuelle.
Automatisation et responsabilisation
-
Tous les changements ont une intégration automatisée (CI). -
Les résultats sont examinés par les pairs et signés par eux. -
Appliquer « l'intégrité à deux personnes" pour les changements d'infrastructure sensibles: l'automatisation promulgue le changement, mais un deuxième pair signe numériquement. -
Liez chaque modification d'infrastructure à un élément de travail ou à un ticket – le pipeline CI devrait échouer s'il ne peut pas lier la modification de code à l'intention. -
Conservez des pistes d'audit immuables des actions d'automatisation dans un magasin de journaux externe (p. ex., blob d'ajout seul ou connecteur SIEM).
Rapports de conformité sur les tests de résilience :
-
Authentification et tests d'identité -
Autorisation et contrôle d'accès -
Protection des données et confidentialité -
Configuration infonuagique et tests d'infrastructure -
Sécurité des applications (OWASP + infonuagique spécifique) -
Sécurité des réseaux et des API -
Conformité et chaîne d'approvisionnement -
Analyse de code (Snyk, Sonarqube) -
Stockez les résultats dans un stockage cloud séparé, mettez en évidence tout changement de statut. -
Effectuez des exercices qui simulent le vol de jetons, les mouvements latéraux ou la corruption des journaux: mesurez le temps nécessaire pour détecter et réagir. -
Intégrez l'ingénierie de sécurité du chaos: par exemple, injectez délibérément des certificats expirés, des jetons révoqués ou désactivez l'authentification multifacteur pour tester si la détection et la récupération se déclenchent. -
Testez la survie des données: simulez la perte de journaux de production et confirmez que votre environnement secondaire d'expédition de billes reste intact. -
Automatisez l'équipe rouge dans une boîte: les analyses planifiées et les tentatives d'élévation de privilèges scritées s'exécutent en continu, avec des résultats intégrés au backlog. -
Encore, tirez parti de l'IA pour signaler les tendances ou les indices cachés. Mais ne vous y fiez pas!
Les responsables de la sécurité aiment se vanter de "suivre les meilleures pratiques Azure". Les attaquants aiment que vous le fassiez aussi. Parce qu'ils savent que ces pratiques exemplaires n'ont pas été écrites pour eux. Ils ont été écrits pour vous vendre la tranquillité d'esprit.
Notre clôture
Les bonnes pratiques et les vérifications feront toujours partie du jeu. Ils ont posé le plancher, mais jamais le plafond. La vraie résilience survient lorsque vous allez au-delà des vérifications et que vous commencez à concevoir des systèmes pour survivre au contact avec les attaquants.
Cela signifie :
- Automatisez en pensant à la récupération: des pipelines qui non seulement se déploient, mais auto-réparent les infrastructures et détectent les dérives.
- Ajoutez des frictions humaines là où ça compte: évaluation par les pairs et intégrité de deux personnes pour les changements sensibles.
- Protégez les données qui comptent le plus : chiffrement au niveau du terrain, sauvegarde et journalisation de survie dans des magasins isolés.
- Testez l'échec, pas seulement la conformité: répétez les violations, semez le chaos et prouvez que vous pouvez vous remettre.
Les attaquants ne se soucient pas de votre note d'audit. Ils se soucient des fissures entre vos commandes. Combler ces lacunes est ce qui transforme le "théâtre de sécurité" en véritable résilience.