Le "Tout en Code" : L'épine dorsale d'une pratique SecDevOps fiable, sécurisée et cohérente
Chez JPSoftWorks, vous savez, nous avons toujours cru que la technologie devait servir les gens avant tout : et non
l'inverse, et oui on insiste. Grâce à cela, et au fil des années, en travaillant dans le domaine du SecDevOps, une vérité est devenue de plus en plus
évidente pour nous: pour créer des systèmes sécurisés, maintenables et de haute qualité, il faut de
l'uniformité. Et l'uniformité ne se produit pas par hasard. Elle résulte d'une volonté de l'intégrer
délibérément à vos processus.
Pour nous, l'un des leviers les plus puissants pour atteindre cette uniformité est la philosophie du "Tout en Code" (Everything as Code, EaC).
Ce n'est pas qu'un slogan accrocheur ou un terme à la mode. C'est une approche disciplinée qui considère
que chaque élément du cycle de vie d'un produit: code applicatif, infrastructure, configurations,
politiques, pipelines, documentation, et même contrôles de conformité, doit être un artefact versionné, révisible et
testable.
Et lorsque vous combinez cette philosophie avec un processus structuré de ramification et de fusion
Git, vous libérez un niveau de cohérence, de traçabilité et d'automatisation qui transforme
fondamentalement votre façon de livrer de la valeur.
Ce que signifie vraiment "Tout en (tant que) Code"
La manière la plus simple d'expliquer le "Tout en Code" est :
Si
cela peut être exprimé dans un fichier, cela doit être placé sous contrôle de version. Idéalement dans un format
propice à la comparaison de contenu.
Cela signifie :
- Code applicatif :
bien sûr, mais aussi…
- Infrastructure en Code
(IaC) : Bicep, Terraform, modèles ARM, playbooks Ansible, etc.
- Configuration en Code
(CaC) : manifestes Kubernetes, paramètres applicatifs, indicateurs de fonctionnalités.
- Politiques en Code
(PaC) : règles de sécurité et de conformité, ex. Open Policy Agent (OPA), définitions Azure
Policy.
- Documentation en
Code : fichiers Markdown, reStructuredText ou AsciiDoc stockés avec le projet.
- Pipelines en
Code : workflows CI/CD en YAML (Azure DevOps, GitHub Actions, GitLab CI).
- Définitions de
tests : tests unitaires, d'intégration, de performance et scripts d'analyses de sécurité.
- Définitions de supervision et
d'alertes : tableaux de bord Grafana, règles Prometheus, définitions d'alertes Azure Monitor.
Cette approche élimine le problème du "spécimen unique" : où la production fonctionne d'une manière, le
développement d'une autre, et où personne ne sait vraiment comment l'environnement de préproduction a été configuré.
Quand tout vit dans Git, il n'existe qu'une seule source de vérité.
Pourquoi Git est la colle qui fait tenir le tout
Le "Tout en Code" est puissant, mais ce n'est pas suffisant en soi. Il faut
une discipline sur la manière dont les changements entrent dans votre dépôt de code.
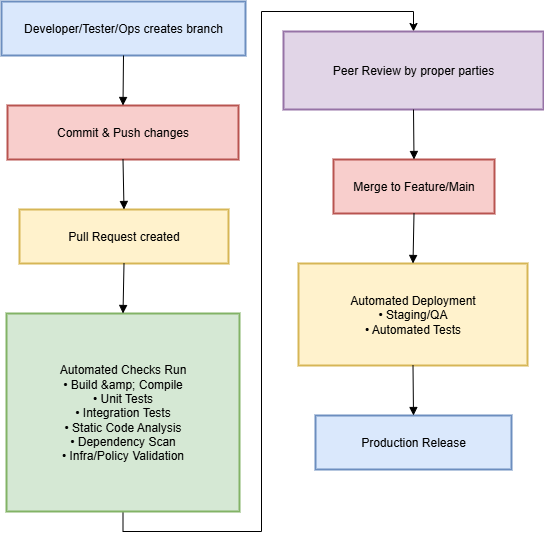
C'est là que Git, et plus précisément une stratégie réfléchie de branches et de fusions, intervient.
Nous avons un principe simple :
Aucun changement n'atteint la branche principale sans révision délibérée et validation
automatisée.
Chaque mise à jour: qu'il s'agisse d'une nouvelle fonctionnalité, d'une modification d'infrastructure, d'un
ajustement de politique ou d'une ligne de documentation, passe par une branche et une demande de tirage (Pull
Request). Cette PR est le point de contrôle où :
- Nous révisons le
changement : un examen humain, par les bonnes personnes.
- Nous exécutons des vérifications
automatisées : tests, analyses de sécurité, validations de politiques.
- Nous décidons
délibérément : fusionner ou non.
Ce n'est pas de la bureaucratie. Ce processus garantit que les changements respectent nos standards de sécurité, de
performance, de conformité et de maintenabilité. C'est l'une des nombreuses façons
dont Security, Development et Operations unissent
leurs forces pour obtenir un produit de meilleure qualité, en un temps record.
L'uniformité grâce à la révision et à l'automatisation
Et voici comment cela fonctionne.
Avec un processus Git/merge bien établi, vous bâtissez l'uniformité au sein de votre
produit. Pour les développeurs, c'est devenu une évidence depuis belle lurette.
Cette pratique s'étend désormais à quatre domaines clés :
1. Cohérence du produit
Qu'il s'agisse de fonctionnalités ou de corrections de bogues, les revues de PR garantissent :
- Que le nouveau code suit les standards
et modèles établis.
- Que les fonctionnalités sont conformes
aux attentes métiers et utilisateurs.
- Que les implications en matière de
sécurité sont traitées avant d'atteindre la production.
Vérifications automatisées possibles :
- Validation de
compilation/build : s'assurer que le code compile proprement dans un environnement cohérent.
- Tests unitaires :
détecter rapidement les régressions.
- Analyse statique du
code : signaler les vulnérabilités potentielles ou mauvaises pratiques (SonarQube, ESLint,
analyseurs Roslyn).
- Analyse des
dépendances : identifier les bibliothèques tierces vulnérables.
2. Uniformité des configurations
La dérive de configuration est un cauchemar récurrent en exploitation. Avec la Configuration en Code :
- Dev, QA et production sont construits à
partir des mêmes fichiers de base.
- Tout changement de configuration passe
par le même processus de PR.
- Les retours arrière se font simplement
via un revert Git.
Vérifications automatisées possibles :
- "Linting" des fichiers de
configuration :
yamllint, terraform validate,
etc.
- Conformité aux
politiques : Azure Policy, vérifications OPA.
- Tests
d'idempotence : s'assurer que rejouer la configuration ne provoque pas de changements
imprévus.
3. Alignement de la documentation
En conservant la documentation dans le même dépôt que le code, on élimine les documents obsolètes ou
contradictoires.
- Les réviseurs peuvent vérifier que la
documentation reflète bien le changement apporté.
- Des processus automatisés peuvent
détecter les liens cassés ou les sections manquantes.
- Des outils comme
mkdocs ou Sphinx peuvent
reconstruire et publier automatiquement la documentation.
Automatisation possible :
- Vérification
orthographique/grammaticale : linting automatisé pour la doc.
- Vérification de couverture
documentaire : s'assurer que les nouvelles fonctionnalités sont documentées.
- Validation des
liens : éviter les références obsolètes.
4. Synchronisation des tests
Les tests vivent aux côtés du code qu'ils valident. Lorsqu'on modifie une fonctionnalité :
- La PR exige la mise à jour ou l'ajout
de tests.
- L'intégration continue exécute ces
tests à chaque changement.
- Les outils de couverture signalent
toute baisse du taux de couverture.
Impossible donc "d'oublier" de mettre à jour les tests : les réviseurs le verront et la pipeline échouera si les
tests ne passent pas.
Les opportunités d'automatisation dans le processus de merge
La PR n'est pas qu'une revue humaine. C'est aussi le point de déclenchement idéal
pour l'automatisation. Nos pipelines de PR peuvent exécuter :
- Build &
Compile : vérifier que le code compile dans un environnement propre.
- Tests unitaires :
validation immédiate de la logique.
- Tests
d'intégration : garantir l'interopérabilité des services.
- Analyse statique du
code : contrôles qualité et sécurité.
- Analyse des
dépendances : détection de bibliothèques vulnérables (SCA).
- Validation
d'infrastructure :
terraform plan ou
Azure ARM/Bicep “What-If”.
- Vérifications de
politiques : contrôle automatisé des règles de sécurité.
- Tests de performance de
référence : détecter les régressions.
- Vérifications de
conformité : SOC 2, ISO 27001 ou règles internes.
- Analyse d'images
Docker : détection de vulnérabilités.
- Détection de
secrets : éviter la publication accidentelle de clés/API.
Cette automatisation shift-left permet de détecter les
problèmes avant qu'ils n'affectent la production.
La sécurité comme résultat intégré
Parce que tout passe par le contrôle de version et la revue de PR, nous intégrons la sécurité dès le départ :
- Aucun changement non
documenté : chaque modification est tracée dans l'historique Git.
- Aucun changement non
autorisé : les permissions Git définissent qui peut fusionner.
- Traçabilité
transparente : visibilité complète sur qui a changé quoi, et pourquoi.
- Analyses de sécurité au moment
de la PR : corriger les vulnérabilités avant la mise en production.
Dans les environnements traditionnels, la sécurité est souvent une étape à la fin de la chaîne.
Avec le "Tout en Code", elle fait partie intégrante du flux. C'est l'un des concepts clés.
Bénéfices concrets
Mettre en place le "Tout en Code" avec un processus Git discipliné apporte à JPSoftWorks et à nos clients :
- Moins d'incidents en
production : la dérive et les changements non documentés sont éliminés.
- Intégration plus
rapide : les nouveaux membres ont l'ensemble du système décrit dans le code.
- Audits
simplifiés : les preuves de conformité sont dans Git.
- Déploiements
prévisibles : ce qui est testé est ce qui est livré.
- Confiance dans le
changement : les vérifications automatisées détectent les régressions tôt.
Et peut-être le plus grand avantage : la confiance. Les équipes font confiance au système car
elles savent que les changements sont délibérés, révisés et testés. Les parties prenantes font confiance aux
livraisons, car elles constatent une fiabilité constante.
Aller plus loin : perspectives futures
Le "Tout en Code" n'est la fin en soi de SecDevOps. Quelques pistes de "Baby steps" additionnelles à explorer:
- Modélisation automatisée des
menaces dans les pipelines de PR.
- Infrastructure
auto-réparatrice déclenchée par des métriques de supervision.
- Revue de PR assistée par
IA pour signaler plus vite les problèmes potentiels.
- Observabilité unifiée en
code : tableaux de bord et alertes versionnés avec les changements applicatifs.
Conclusion
Chez JPSoftWorks, le "Tout en Code" est plus qu'un choix technique : c'est un choix culturel. Il exprime que :
- Nous valorisons la transparence.
- Nous valorisons le changement délibéré.
- Nous croyons que l'automatisation doit
amplifier l'expertise humaine, pas la remplacer.
- Nous croyons que la sécurité,
la cohérence et la qualité sont intégrées : pas ajoutées après coup.
En combinant la philosophie du "Tout en Code" avec un processus de fusion Git discipliné, nous nous assurons que
produits, configurations, documentation et tests évoluent ensemble : revus par les bonnes
personnes et validés par l'automatisation avant de toucher la production.
C'est ainsi que nous aidons à créer des logiciels qui ne fonctionnent pas seulement aujourd'hui, mais qui seront
fiables demain.
Si vous souhaitez voir comment cette approche peut renforcer et sécuriser vos processus de livraison,
discutons-en. Chez JPSoftWorks, nous faisons en sorte que les outils et la technologie travaillent pour les
gens, avant tout. Contactez Nous.